

Third-party app integrations have become foundational to modern software development. From streamlining workflows to accelerating feature deployment, integrations help organizations build more robust, feature-rich applications while focusing on their core value propositions.
The Benefits of Third-Party App Integrations
Common use cases
- Authentication: Tools like Auth0 and PropelAuth simplify user sign-up and login workflows.
- Monitoring and observability: Platforms like Datadog and New Relic provide insights into performance and uptime.
- Error reporting: Tools such as Sentry and Bugsnag alert developers to issues as they happen.
- Sales and marketing: CRMs like Salesforce and HubSpot help drive customer acquisition and retention.
- Web analytics: Google Analytics, Mixpanel, and Segment offer behavioral insights.
- LLM integrations: AI tools like OpenAI, Anthropic, Google Gemini, and others are rapidly being integrated into workflows for customer support, content generation, and internal knowledge search.
Advantages
- Faster time to market: Teams can deliver features rapidly by avoiding the overhead of building everything in-house.
- Reduced development costs: Buying best-in-class functionality is often cheaper than building and maintaining it.
- Engineering focus: Developers can focus on what differentiates their product instead of reinventing common tools.
The Dangers of Third-Party App Integrations
While third-party services unlock massive benefits, they also introduce risks, especially when privacy is not embedded by design.
SDKs full of security risks
Most integrations rely on SDKs that introduce:
- Open-source vulnerabilities: malicious or outdated dependencies. A well known example is the event-stream incident, where a widely used npm package was found to include a malicious dependency targeting crypto wallets.
- Scope creep: once an SDK is embedded, it may request or collect more data than originally anticipated. These layers of abstraction make it difficult to identify data exposure risks.
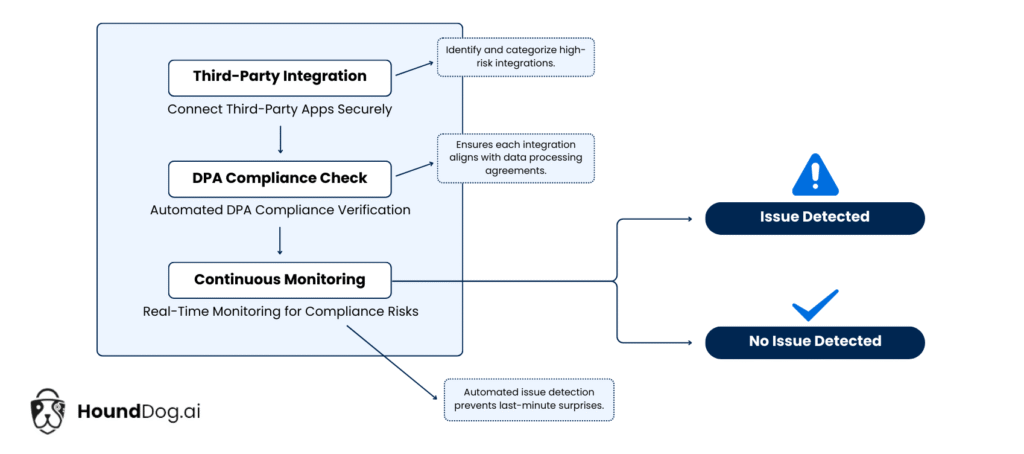
How Data Processing Agreement Violations Happen
Despite the benefits, third-party integrations often become privacy minefields. Developers, and increasingly AI code assistants, can unintentionally introduce risks by oversharing sensitive data with third-party services, bypassing established data processing agreements (DPAs).
Rigorous vendor onboarding, but no continuous monitoring
Assume a company has developed a customer-facing application that integrates with Datadog for continuous monitoring, Google Analytics for tracking user sessions, Salesforce for updating customer data, and OpenAI to enable personalization. The appendix of most DPAs documents the categories of data subjects, categories of personal information, sensitive data processed, and the nature and purpose of processing.
In this scenario, the agreed-upon categories of personal information allowed for each vendor are as follows:
| Platform | Categories of Personal Information Allowed in the DPA |
|---|---|
| Datadog | hostname, ipAddress, deviceType |
| OpenAI | role, industry, companySize, age, gender |
| Google Analytics | ipAddress, deviceType, browserUsed |
| Salesforce | firstName, lastName, email, phoneNumber, role, companyName, industry |
Security, privacy, and third-party risk management teams often spend significant time during vendor onboarding ensuring that vendors meet compliance requirements and agree to DPA terms. Unfortunately, many companies stop there. Once a vendor is onboarded, few controls are put in place to continuously monitor adherence to the agreed-upon data flows.
This is a critical gap. It is not just the vendor's responsibility to uphold the DPA. Your own developers play a major role. If an engineer mistakenly sends unauthorized fields (such as email or SSN) to a vendor like Datadog or OpenAI, the breach originates from your side, even if the vendor's own systems are secure and compliant.
Once that sensitive data reaches a third-party system, you are at the mercy of their internal data handling practices. In many cases, the data becomes deeply embedded within their ecosystem, replicated across logs, caches, dashboards, backups, and internal analytics tools. Deleting or correcting that data after the fact can be operationally complex and legally uncertain.
Strong vendor onboarding is not enough. Without continuous controls that keep data sharing in code aligned with what was contractually agreed, data overexposure is not just theoretical. It is inevitable.
Real examples: accidental sharing of entire user objects
As developers build integrations with analytics, observability, or CRM tools, it is common to pass contextual data to these platforms for better insights. Without clear guardrails, developers or AI coding assistants may accidentally transmit full user objects, exposing PII such as names, emails, phone numbers, and even Social Security Numbers. This often happens when objects are spread into function parameters or logged without filtering.
All examples below use this shared User object:
interface User {
id: string;
email: string;
ssn: string;
firstName: string;
lastName: string;
phoneNumber: string;
role: string;
companyName: string;
industry: string;
}
Example 1: Datadog
function handleLogin(user: User) {
// BAD: full user object, violates the DPA
datadogLogger.info("User logged in", { user });
// GOOD: only metadata permitted by the DPA
const { deviceType, ipAddress, hostname } = getSystemInfo();
datadogLogger.info("User logged in", { deviceType, ipAddress, hostname });
}
Why it is risky: Datadog's DPA allows metadata like hostname, ipAddress, and deviceType. Logging the full user object violates this agreement and may expose sensitive data into Datadog logs, which are hard to scrub post-ingestion.
Example 2: Google Analytics
function trackUserSignup(user: User) {
// BAD: object spread leaks every field
gtag("event", "user_signup", { ...user });
// GOOD: only permitted fields
const { deviceType, browserUsed, ipAddress } = getDeviceInfo();
gtag("event", "user_signup", { deviceType, browserUsed, ipAddress });
}
Why it is risky: Google Analytics is not contractually permitted to receive PII like names, emails, or SSNs. Sending the full user object, especially via object spread, can leak sensitive information that is stored and processed against DPA terms.
Example 3: Salesforce
function syncUserToSalesforce(user: User) {
// BAD: spreads the SSN and internal IDs into Salesforce
sendToSalesforce("lead_create", { ...user });
// GOOD: explicit, DPA-permitted fields only
sendToSalesforce("lead_create", {
firstName: user.firstName, lastName: user.lastName,
email: user.email, phoneNumber: user.phoneNumber,
companyName: user.companyName, role: user.role, industry: user.industry });
}
Why it is risky: although Salesforce may allow many fields under the DPA (name, contact info, and so on), PII like SSNs and user IDs are typically out of scope. Spreading the full object risks violating these agreements, especially if data visibility in Salesforce is not tightly controlled.
Example 4: OpenAI, tainted variables in prompts
Variables that begin clean may become tainted with PII. Developers and AI assistants often fail to catch this, especially when constructing dynamic prompts for AI models.
let promptContext = {
audience: "Customer",
notes: "Welcome to our platform.",
};
// BAD: the variable becomes tainted with PII
promptContext.audience = `${user.firstName} ${user.lastName}`;
promptContext.notes = `Welcome ${user.email} to the ${user.industry} platform.`;
// GOOD: use only permitted metadata in the prompt
const prompt = `Generate a welcome message for a ${user.role} in the ${user.industry} sector.`;
DPA breach summary
| Scenario | Platform | Breach (Not Allowed by DPA) | Allowed by DPA |
|---|---|---|---|
| Full user object to Datadog | Datadog | email, ssn, firstName, lastName, phoneNumber, role, companyName, industry | hostname, ipAddress, deviceType |
| Tainted variables in OpenAI prompt | OpenAI | email, firstName, lastName | role, industry, companySize, age, gender |
| Full user object to Google Analytics | Google Analytics | email, ssn, firstName, lastName, phoneNumber, role, companyName, industry | ipAddress, deviceType, browserUsed |
| Full user object to Salesforce | Salesforce | ssn | firstName, lastName, email, phoneNumber, role, companyName, industry |
Policy violations by framework
When sensitive data is shared with third-party integrations beyond the scope of an established DPA, it constitutes a clear violation of applicable regulations, including:
- Personally Identifiable Information (PII): GDPR, CCPA, GLBA, PIPEDA, APPI, NIST 800-53, ISO/IEC 29100, and similar laws
- Protected Health Information (PHI): HIPAA
- Cardholder Data (CHD): PCI DSS
Best practices
- Avoid sending complete user objects to third-party services.
- Sanitize sensitive data only when its collection is strictly necessary. Prioritize data minimization: if the data is not essential, exclude it entirely. This is more secure than relying on sanitization alone, especially for LLM prompts and data sent to analytics or observability platforms.
- Refer to your Data Processing Agreement and enforce permitted fields through code.
- Build utility functions that extract and return only the data fields allowed under your compliance requirements.
Methods of Tracking Third-Party Data Flows and Enforcing Data Minimization
| Method | Layer | Pros | Cons |
|---|---|---|---|
| Static Code Analysis | Code | Early detection pre-deployment, scales across repos, enforces privacy by design, works for developer and AI-generated code | May miss runtime-generated data |
| Manual Code Reviews | Code | Human judgment, can catch complex context-based issues | Time-consuming, not scalable, prone to human error |
| API Gateway Monitoring | API | Centralized control over API traffic, can log, redact, or block | Requires all traffic to pass through the gateway, misses traffic that bypasses it such as SDKs and internal services |
| Network Proxy | Network | No need to modify app code | Hard to scale across microservices, lacks understanding of data context or meaning |
| Data Loss Prevention (DLP) | Network / Storage | Detects sensitive data in transit or at rest, integrates with the broader security stack | Reactive rather than preventative, lacks visibility into app-layer data flows and third-party SDKs |
While API and network-level tools provide valuable safeguards, they are fundamentally reactive. These solutions sanitize data in transit but do not prevent the collection of unnecessary data, falling short of enforcing true data minimization, a cornerstone of privacy by design.
DIY PII detection in code scanning does not scale
Hardcoded RegEx rules are brittle, difficult to maintain, and often limited to basic log detection. Most DIY efforts stall before scaling meaningfully, especially when it comes to tracking data flows through third-party SDKs. These efforts lack context around data sensitivity, awareness of sanitization or transformations, and visibility into where data ends up. Complexity grows exponentially when trying to account for every RegEx variation per sensitive data type, variations in field names and object nesting, and all SDK invocations scattered across large codebases. As codebases evolve, accurate coverage becomes nearly impossible to maintain, making DIY approaches unsustainable for privacy and compliance at scale.
HoundDog.ai: The Privacy by Design Code Scanner Purpose-Built for PII Detection and Data Mapping
HoundDog.ai empowers security, privacy, and engineering teams to catch sensitive data leaks and privacy risks before code is deployed. Built from the ground up to enforce privacy by design, the static code scanner enforces data minimization and maps sensitive data flows across all storage mediums and third-party integrations, all directly within your source code.
Blazing fast, built in Rust for scale
The scanner is written entirely in Rust, making it extremely fast and lightweight. It can scan millions of lines of code in under a minute, with virtually no impact on developer velocity. It is built for large monolithic or microservices codebases, high-frequency CI/CD pipelines, and multi-language repositories.
Unmatched detection accuracy across the full data lifecycle
HoundDog.ai goes far beyond regular expressions, delivering precise, context-aware detection of sensitive data elements (PII, PHI, PIFI, CHD, and other regulated identifiers), risky data sinks (including hundreds of third-party tools and SDKs across observability, analytics, sales, marketing, and AI), and sanitization gaps, flagging data only when it is unsanitized to reduce noise and surface real risks.
Endlessly flexible and built for compliance
Tailor detection logic to your unique tech stack and regulatory requirements: define custom data element types based on internal policies or legal obligations, apply granular allowlists to enforce which data elements are permitted per data sink or third-party integration, and add custom sanitization functions to meet your internal security standards. Whether you are aligning with GDPR, HIPAA, PCI DSS, or internal policies, HoundDog.ai adapts to your needs.
Enterprise ready, developer first, CI integrated
HoundDog.ai fits directly into existing engineering workflows: connect to GitHub, GitLab, or Bitbucket to scan pull requests, block risky changes, and leave actionable code comments. Use Managed Scans to offload scan execution for continuous, hands-off coverage across all repositories with compliance-grade reporting. Or inject scans into pipelines via GitHub Actions, GitLab CI, Jenkins, and more.
Privacy by design for AI applications
AI applications introduce a unique set of risks, and HoundDog.ai is purpose-built to address them. The scanner detects sensitive data leaks in AI-specific mediums including prompt logs, embedding stores, and temporary files, and flags unsanitized inputs passed into LLMs. This ensures AI features comply with your privacy standards before anything reaches production.